netto <- 120 + 89 + 56
brutto <- netto * 1.19
netto
bruttoSoftware
Die Anwendung statistischer Methoden erfolgt heute in der Regel mittels entsprechender Software. Für unsere Statistikvorlesung werden wir die statistische Programmiersprache R einsetzen. Die folgende Einführung in R soll Ihnen den Einstieg erleichtern.
TippMini-Orientierung
Nach diesem Kapitel können Sie
- sich in der Posit Workbench anmelden und eine RStudio-Session starten,
- einfache Berechnungen und Zuweisungen in R durchführen,
- typische Datenstrukturen in R einordnen und ansprechen,
- häufige Einstiegsfehler selbst erkennen und beheben.
1 R und Posit
R ist eine freie Programmiersprache für statistische Berechnungen und Grafiken. Sie ist eine der wichtigsten und am häufigsten verwendeten Programmiersprachen im Data-Science-Kontext. RStudio ist eine integrierte Entwicklungsumgebung (IDE) für die Programmiersprache R und ein wichtiges Werkzeug bei der Arbeit mit R. R ist aktuell auf den wichtigsten Plattformen (Windows, Mac, Linux) verfügbar. Die Basis-Version von R sowie sämtliche Pakete sind über das “Comprehensive R Archive Network” (CRAN) abrufbar, das unter https://cran.r-project.org erreichbar ist. Das Unternehmen hinter RStudio heißt heute Posit.
HinweisBegriffe kurz erklärt
- IDE: Entwicklungsumgebung zum Schreiben und Ausführen von Code (hier: RStudio).
- CRAN: Zentrale Plattform für R und viele Zusatzpakete.
- Environment: Ihre aktuelle Arbeitsumgebung mit allen Objekten, die Sie erstellt haben.
1.1 Posit Workbench der FH Münster
An der FH Münster haben Sie Zugang zur Posit Workbench. Diese ist erreichbar unter der Domain r-workbench.fh-muenster.de.
Zur Anmeldung verwenden Sie Ihre FH Kennung und das dazugehörige Passwort. Außerhalb des FH-Datennetzes ist die VPN Verbindung notwendig1. Die Einwahl per VPN ist nur über eine Zweifaktorauthentifizierung möglich2.
Nach der Anmeldung erscheint der Launcher für eine neue Session (siehe Abbildung 1). Dort können Sie auswählen, mit welcher IDE Sie arbeiten möchten, z.B. RStudio Pro, Positron Pro, JupyterLab oder VS Code. Zusätzlich können Sie einen Session-Namen vergeben und je nach Vorgaben der Workbench Ressourcen wie CPU und Arbeitsspeicher konfigurieren.
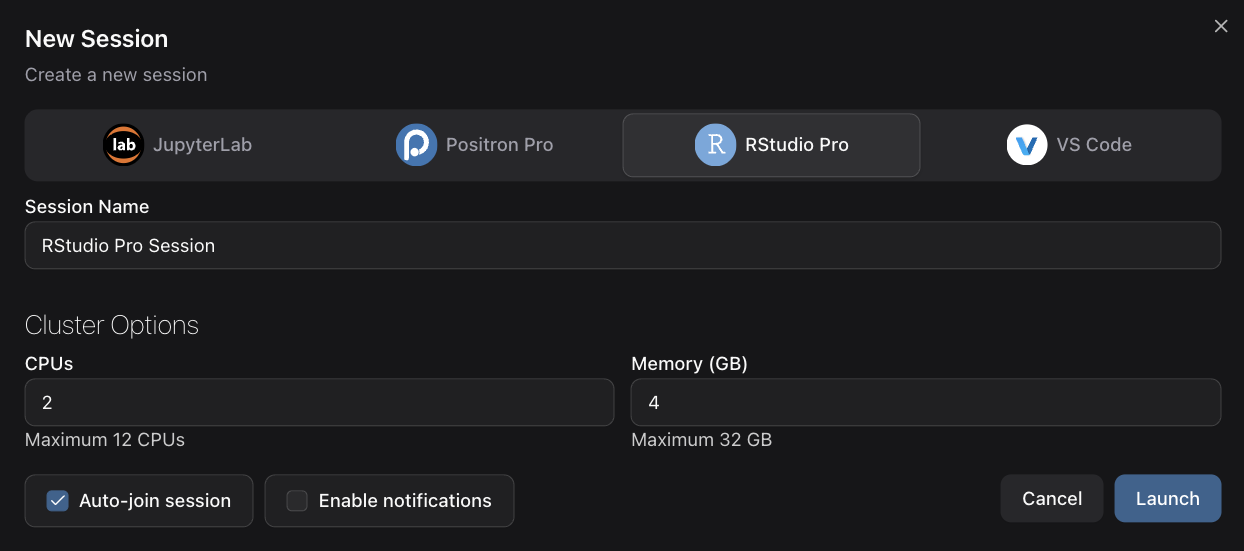
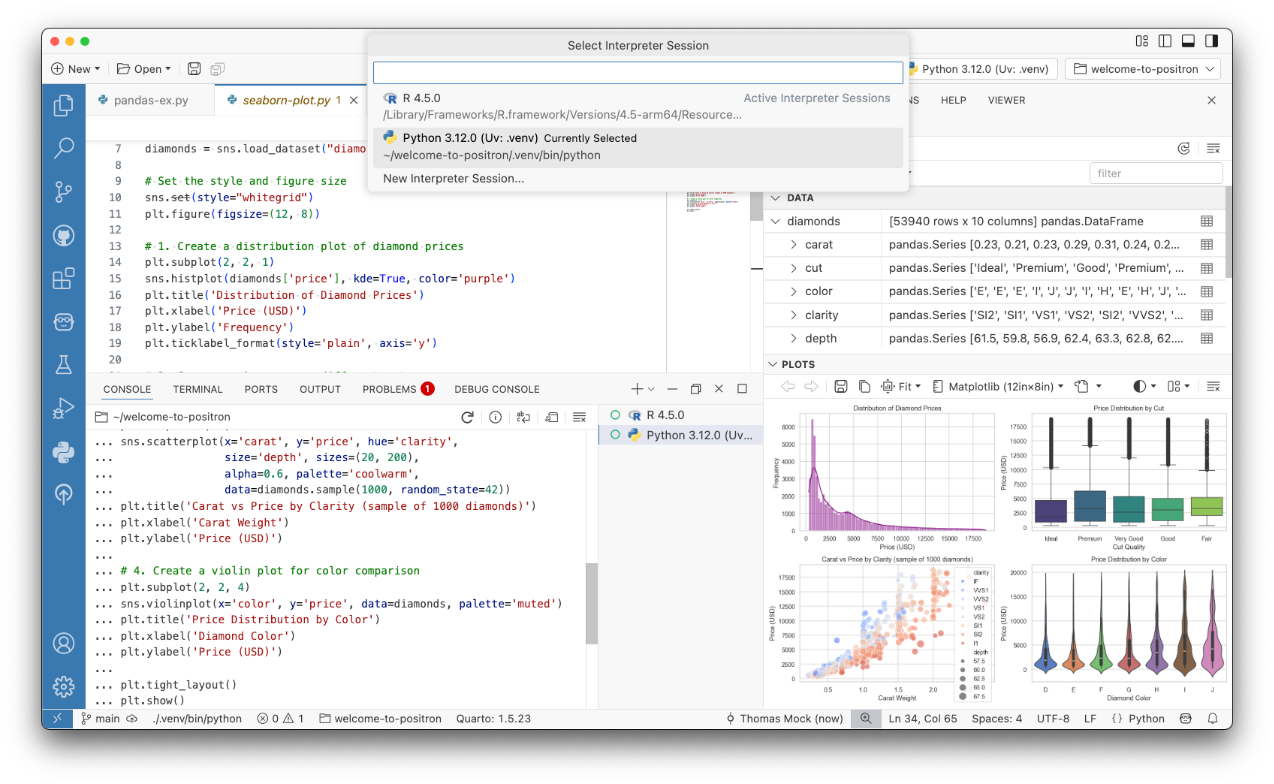
Für diese Vorlesung ist RStudio Pro die Standardumgebung. Die anderen IDEs können Sie bei Bedarf nutzen, die Erklärungen und Beispiele in diesem Skript beziehen sich aber auf RStudio. Eine Beispielansicht von Positron sehen Sie in Abbildung 2.
VorsichtMini-Übung 1
- Melden Sie sich in der Posit Workbench an.
- Starten Sie eine RStudio Pro-Session.
- Geben Sie der Session einen eigenen Namen.
- Beenden Sie die Session sauber über die Oberfläche.
1.2 Alternative 1: Installation von R und RStudio
Sie können R und RStudio auch lokal auf Ihrem eigenen Rechner installieren. Dazu können beide Softwarepakete heruntergeladen werden:
- Das Softwarepaket R ist verfügbar unter cran.r-project.org.
- Das graphische Frontend RStudio ist verfügbar unter rstudio.com.
Anschließend müssen beide Programme in genau dieser Reihenfolge installiert werden (zunächst R, dann RStudio). Eventuell müssen noch zusätzliche Pakete nachinstalliert werden.
1.3 Alternative 2: Posit Cloud
Posit Cloud ist eine cloudbasierte Lösung, mit der jeder online Statistik betreiben, teilen, lehren und lernen kann. Sie können Posit Cloud kostenlos nutzen, die Nutzungsdauer ist allerdings auf 25 Stunden pro Monat begrenzt. Um Posit Cloud nutzen zu können, erstellen Sie sich dazu einen Account unter posit.cloud.
2 Verwendung von R und RStudio
Während R lediglich eine Konsole mit einem einfachen Editor zur Verfügung stellt, erweitert die Entwicklungsumgebung von RStudio die Funktionalität von R um viele weitere nützliche Tools.
Dabei unterscheiden sich die Server- und Desktop-Version von RStudio nicht wesentlich in ihrer Verwendung. Nur beim Laden von lokal gespeicherten Daten oder der Installation von Paketen gibt es kleinere Unterschiede zu beachten.
TippErste Schritte (empfohlen)
- In der Workbench RStudio Pro starten.
- Ein neues Skript über
File -> New File -> R Scriptanlegen. - Skript sofort speichern (z.B.
erstes_skript.R). - Zeilenweise mit
Strg + Enterausführen. - Am Ende der Arbeit die Session sauber beenden.
2.1 Aufbau von RStudio
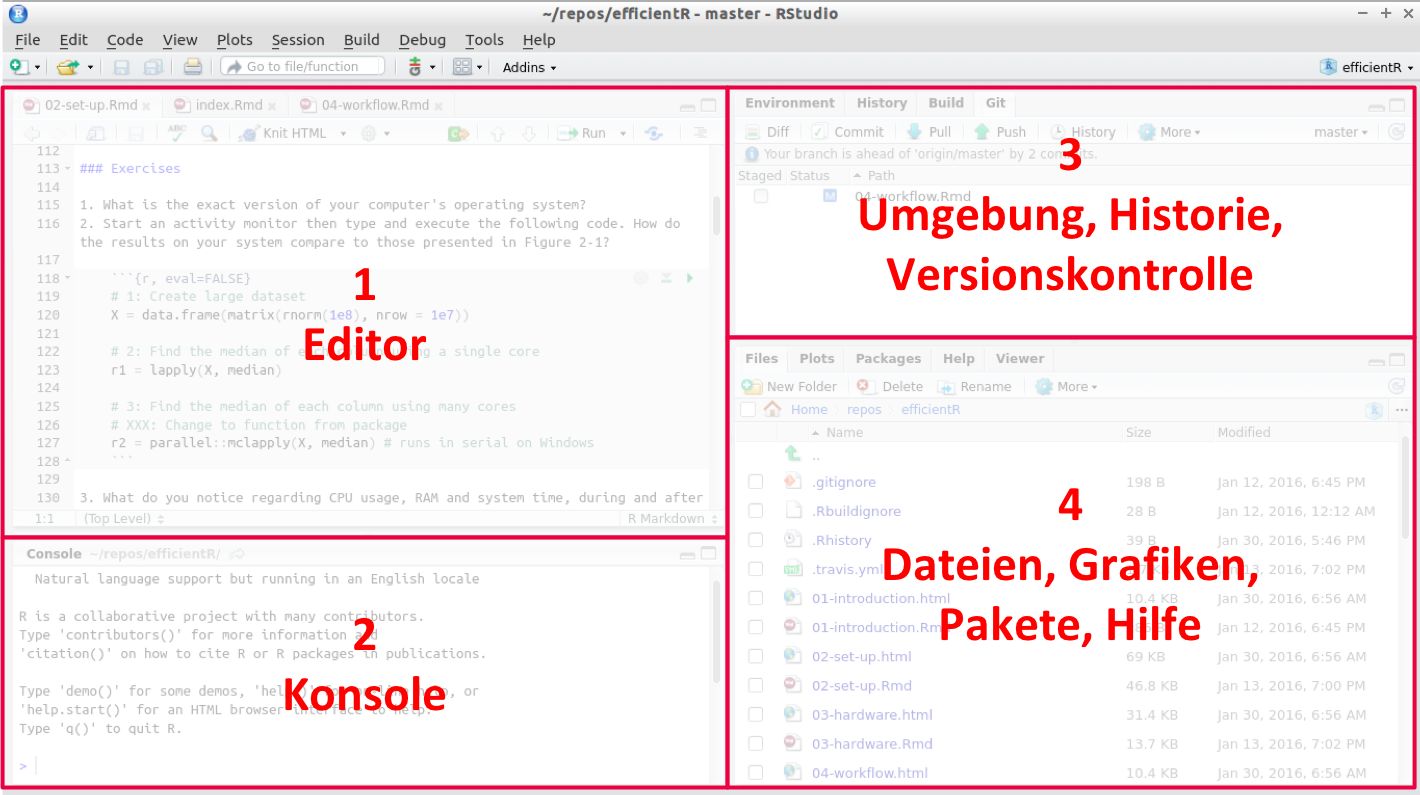
RStudio zeigt standardmäßig verschiedene “Panes” (engl. Fensterausschnitte) (Abbildung 3). Diese Bereiche sind für unterschiedliche Aufgaben der Entwicklungsumgebung konzipiert. Sie lassen sich beliebig in der Größe verändern, auch die Inhalte lassen sich im Menü anpassen. Einige Panes können auch in einem weiteren (Browser-)Fenster angezeigt werden, was hilfreich ist, wenn man mit mehreren Monitoren arbeitet.
Im Wesentlichen lassen sich die Bereiche der Oberfläche nach ihren Aufgaben unterteilen, wie in Abbildung Abbildung 3 dargestellt.
2.1.1 Editor (1)
Im Editor werden standardmäßig R Programme erstellt. Diese enthalten eine Abfolge von Kommandos, Funktionen, Funktionsaufrufen etc., die in R ausgeführt werden sollen. Diese können in .R Dateien für die spätere Weiterbearbeitung und Verwendung abgespeichert werden.
2.1.2 Konsole (2)
Die Konsole bzw. Kommandozeile ist ein Eingabebereich für die Steuerung von R. Eingaben in die Konsole werden vom R Interpreter ausgewertet und die Ergebnisse der Berechnung wieder in der Konsole ausgegeben. R Skripte, welche im Editor erstellt werden, werden beim Ausführen in die Konsole gespielt und dort ausgeführt.
2.1.3 Umgebung, Historie, Versionskontrolle (3)
In diesem Bereich werden nützliche Informationen während der Arbeit mit R Skripten angezeigt. So werden beispielsweise alle in der Umgebung (Environment) definierten Variablen angezeigt, die Historie aller ausgeführten Befehle aufgelistet und es gibt die Möglichkeit zur Versionskontrolle.
2.1.4 Dateien, Grafiken, Pakete, Hilfe (4)
Über diesen Bereich haben Sie Zugriff auf das Dateisystem des RStudio Servers, Sie können also auf Ihre dort abgelegten Dateien zugreifen (R-Skripte, Datensätze, exportierte Abbildungen etc.). Bei der Desktop-Version können Sie entsprechend auf das Dateisystem Ihres Rechners zugreifen. Wenn Sie mit R Grafiken erstellen, werden diese in diesem Pane angezeigt. Sie haben außerdem die Möglichkeit, die Abbildungen abzuspeichern. Außerdem gibt es die Möglichkeit über den Reiter ‘Packages’ zusätzliche Pakete für R zu installieren bzw. installierte Pakete zu aktualisieren. Schließlich ist eine der wichtigsten Funktionen in diesem Bereich die Hilfe: Sie können auf die Hilfe und Dokumentation jeder einzelnen R-Funktion zugreifen.
2.2 Wichtige Tastenkürzel in RStudio
Einige Tastenkürzel beschleunigen die Arbeit deutlich:
| Aktion | Windows/Linux | macOS |
|---|---|---|
| Aktuelle Zeile/Auswahl ausführen | Strg + Enter |
Cmd + Enter |
| Gesamtes Skript ausführen (Source) | Strg + Shift + S |
Cmd + Shift + S |
Zuweisungspfeil <- einfügen |
Alt + - |
Option + - |
| Zeile(n) auskommentieren | Strg + Shift + C |
Cmd + Shift + C |
| Konsole leeren | Strg + L |
Cmd + L |
| Laufenden Befehl abbrechen | Esc |
Esc |
| Hilfe zur Funktion öffnen | F1 |
F1 |
Weitere Shortcuts finden Sie im offiziellen RStudio IDE Cheat Sheet: https://posit.co/resources/cheatsheets/
3 Grundlegende Befehle
3.1 Konsole lesen
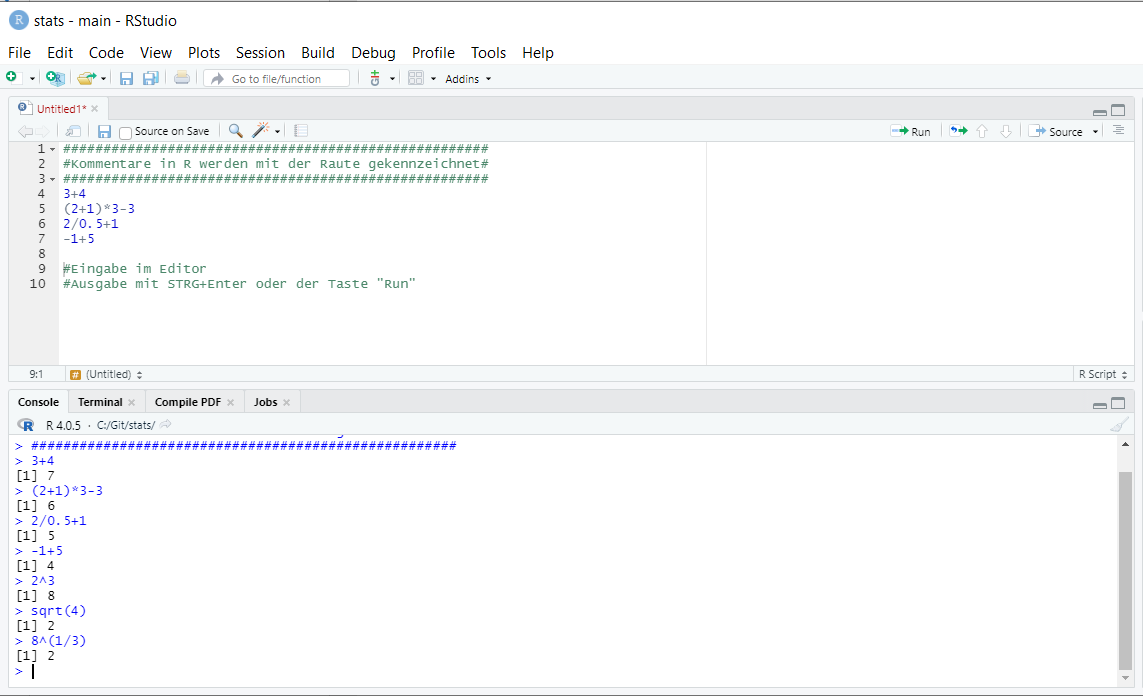
Im Editor wird Code geschrieben und mit Strg + Enter (bzw. Cmd + Enter) ausgeführt. In der Konsole sehen Sie dann Eingabe und Ausgabe (siehe Abbildung 4).
HinweisLegende zur Konsole
>kennzeichnet eine Eingabe in der Konsole.- Zeilen darunter sind die Ausgabe von R.
[1]markiert den Index des ersten ausgegebenen Elements.
3.2 Operatoren
Operatoren verbinden Werte oder Ausdrücke miteinander.
- Arithmetische Operatoren berechnen Zahlenwerte.
- Vergleichsoperatoren prüfen Beziehungen und liefern
TRUEoderFALSE. - Logische Operatoren verknüpfen mehrere Wahrheitswerte.
| Kategorie | Symbol | Wirkung | Input | Output |
|---|---|---|---|---|
| Arithmetik | + |
Addition | 3 + 4 |
7 |
- |
Subtraktion | 10 - 3 |
7 |
|
* |
Multiplikation | 2 * 4 |
8 |
|
/ |
Division | 9 / 2 |
4.5 |
|
^ |
Potenzieren | 2^3 |
8 |
|
| Vergleich | > |
größer als | 7 > 5 |
TRUE |
>= |
größer/gleich | 5 >= 5 |
TRUE |
|
< |
kleiner als | 2 < 1 |
FALSE |
|
<= |
kleiner/gleich | 2 <= 2 |
TRUE |
|
== |
gleich | 3 == 4 |
FALSE |
|
!= |
ungleich | 3 != 4 |
TRUE |
|
| Logik | & |
logisches UND | (2 < 3) & (4 > 1) |
TRUE |
| |
logisches ODER | (2 < 3) | (4 < 1) |
TRUE |
|
! |
logisches NICHT | !(3 < 2) |
TRUE |
VorsichtMini-Übung 2
Berechnen Sie den Nettoumsatz von 3 Positionen und den Bruttoumsatz bei 19% USt:
3.3 Funktionsaufrufe in R
Funktionen werden in R so aufgerufen:
funktionsname(argument1, argument2, ...)Eine Funktion hat meist
- obligatorische Argumente (müssen gesetzt werden),
- optionale Argumente (haben oft Default-Werte).
Argumente können auf drei Arten übergeben werden:
- Benannt (empfohlen):
round(x = 5.1234, digits = 2) - Teilweise benannt:
round(5.1234, digits = 2) - Nur über Reihenfolge:
round(5.1234, 2)
Viele Funktionen haben Default-Werte. Bei round() ist z.B. digits = 0 voreingestellt:
round(5.1234)[1] 5Die benannte Schreibweise ist bei mehreren Argumenten klarer und reduziert Fehler, weil die Bedeutung jedes Arguments direkt sichtbar ist.
3.4 Kommentare mit #
Alles, was nach # in einer Zeile steht, wird von R nicht ausgeführt. Kommentare helfen, Code zu strukturieren und nachvollziehbar zu dokumentieren.
# Monatsumsätze in EUR
umsatz <- c(1200, 980, 1430, 870)
# Mittelwert berechnen
mean(umsatz)[1] 1120Typische Einsatzbereiche:
- Abschnittsüberschriften im Skript (z.B.
# Daten einlesen,# Auswertung,# Visualisierung) - kurze Hinweise zur Bedeutung von Variablen
- Notizen zu offenen Punkten (z.B.
# TODO: Ausreißer prüfen)
3.5 Häufige Funktionen
Die folgenden Funktionen werden im Einstieg besonders häufig verwendet:
| Funktion | Zweck | Input | Output | Erläuterung |
|---|---|---|---|---|
abs() |
Absolutbetrag | abs(-2) |
2 |
Vorzeichen wird entfernt |
round() |
Runden | round(5.1234, 2) |
5.12 |
2 Nachkommastellen |
sqrt() |
Quadratwurzel | sqrt(4) |
2 |
nur für nichtnegative Werte reell |
log() |
Natürlicher Logarithmus | log(1) |
0 |
Basis e |
log10() |
Logarithmus zur Basis 10 | log10(10) |
1 |
häufig in Skalen/Plots |
exp() |
Exponentialfunktion | exp(1) |
2.718282 |
entspricht e^1 |
sum() |
Summe | sum(c(2,4,6)) |
12 |
addiert alle Werte |
mean() |
Mittelwert | mean(c(2,4,6)) |
4 |
arithmetisches Mittel |
HinweisMerken
In R ist das Dezimaltrennzeichen ein Punkt (z.B. 3.5), nicht das Komma.
3.6 Pipe |> in Base R
Seit R 4.1 gibt es in Base R den Pipe-Operator |>. Mit der Pipe wird das Ergebnis links als erstes Argument an die Funktion rechts weitergegeben.
umsatz <- c(1200, 980, 1430, 870, 2100)
umsatz |> mean()[1] 1316Der große Vorteil: mehrere Verarbeitungsschritte lassen sich als klarer Ablauf von links nach rechts schreiben. Das entspricht oft genau dem gedanklichen Vorgehen bei einer Analyse.
Typische Vorteile sind:
- Bessere Lesbarkeit: statt stark verschachtelter Funktionsaufrufe stehen die einzelnen Schritte untereinander.
- Nachvollziehbare Reihenfolge: die Reihenfolge der Transformationen ist direkt sichtbar.
- Einfachere Fehlersuche: einzelne Schritte können leichter isoliert und getestet werden.
Damit kann man Verarbeitungsschritte übersichtlich hintereinander schreiben:
umsatz <- c(1200, 980, 1430, 870, 2100)
umsatz |>
sqrt() |>
round(2)[1] 34.64 31.30 37.82 29.50 45.83Ohne Pipe wäre dieselbe Berechnung stärker verschachtelt:
round(sqrt(umsatz), 2)[1] 34.64 31.30 37.82 29.50 45.83Der Unterschied wird bei längeren Ketten noch deutlicher:
umsatz <- c(1200, 980, 1430, 870, 2100)
umsatz |>
log() |>
mean() |>
round(3)[1] 7.132round(mean(log(umsatz)), 3)[1] 7.132
HinweisHinweis zur Pipe
Mit |> wird standardmäßig immer in das erste Argument der nächsten Funktion gepiped.
3.7 Hilfe und typische Fehler
Für alle Funktionen in R kann eine Hilfefunktion aufgerufen werden. Mit ?(funktion) oder help(funktion) öffnen Sie die Dokumentation. args(funktion) zeigt die Argumente einer Funktion, example(funktion) zeigt Beispielaufrufe (siehe Abbildung 5).
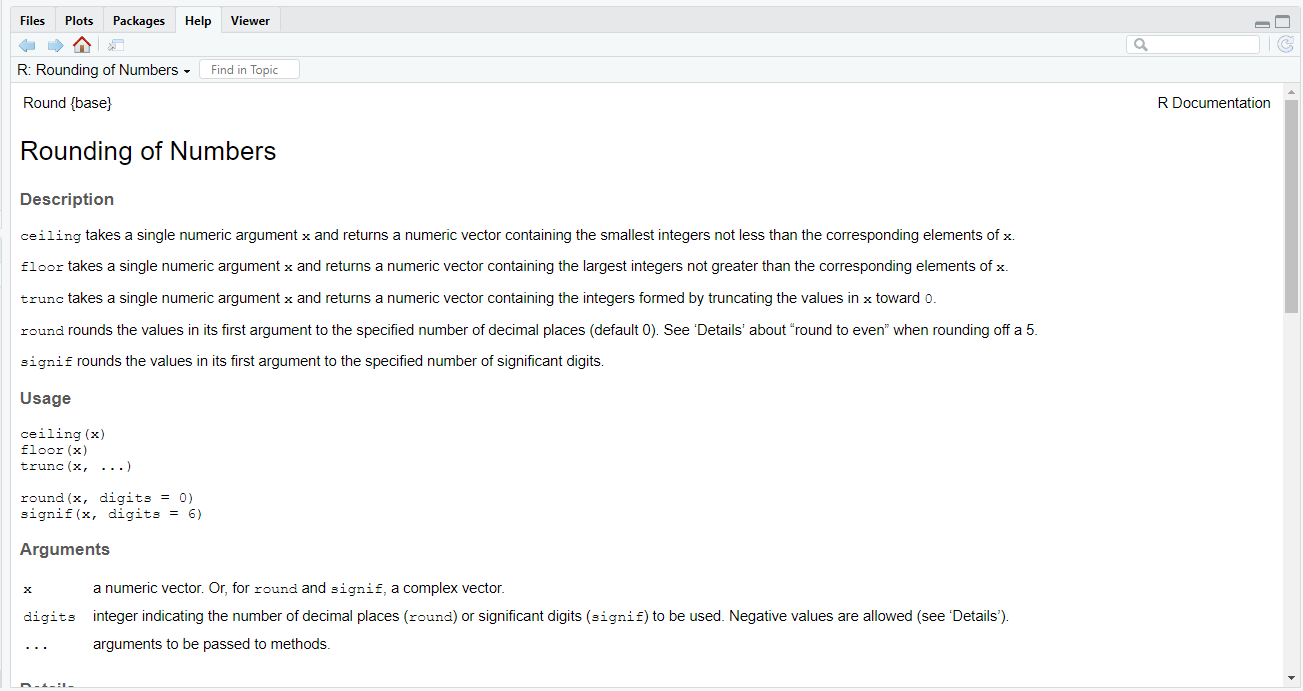
Eine typische Hilfeseite in R enthält:
- Description: Was macht die Funktion?
- Usage: Wie lautet die Syntax?
- Arguments: Welche Argumente gibt es, welche sind optional?
- Value: Was wird zurückgegeben?
- Examples: Beispiele zum Ausprobieren.
Zusätzlich gibt es für viele Pakete sogenannte Vignetten (längere Anleitungen mit zusammenhängenden Beispielen).
Aufruf z.B. über vignette() oder vignette(package = "dplyr").
WichtigHäufige Fehlermeldungen am Anfang
object 'x' not found: Objekt wurde noch nicht erstellt oder anders geschrieben (xist nichtX).unexpected symbol/unexpected ',': Tippfehler oder fehlendes Trennzeichen.- Prompt zeigt
+statt>: Eingabe ist unvollständig (z.B. Klammer oder Anführungszeichen nicht geschlossen). Abbruch mitEsc. - Dezimaltrennzeichen: Punkt statt Komma verwenden (
3.5statt3,5).
VorsichtMini-Übung 3
Prüfen Sie mit logischen Operatoren:
umsatz <- 1250
ist_premium <- TRUE
umsatz > 1000
umsatz > 1000 & ist_premium
umsatz > 2000 | ist_premium4 Objekte, Zuweisungen und Environments
Grundsätzlich lassen sich Objekte neuen Variablen mit Hilfe eines Pfeils <- zuweisen. Wollen wir zum Beispiel der Variable x den Wert 5 zuweisen, y den Wert 2 und z den Wert 1, so schreiben wir
x <- 5
y <- 2
z <- 1Wenn wir dann im Folgenden den Wert von x ansehen möchten, geben wir einfach x ein und erhalten das Resultat zurück:
x[1] 5Wir können mit x und y nun auch Berechnungen anstellen, so ergibt sich \(x^y = 5^2\) mit
x^y[1] 25Zuweisungen auf ein schon bestehendes Objekt, überschreibt dieses:
a <- 1
a <- 2
a[1] 2Mit einer Zuweisung wird ein Objekt also erstellt und ist in der Arbeitsumgebung (Environment) von nun an verfügbar. In RStudio können wir diese Objekte auch in dem entsprechenden oberen rechten Fensterabschnitt im Reiter “Environment” sehen (siehe Abbildung 6).
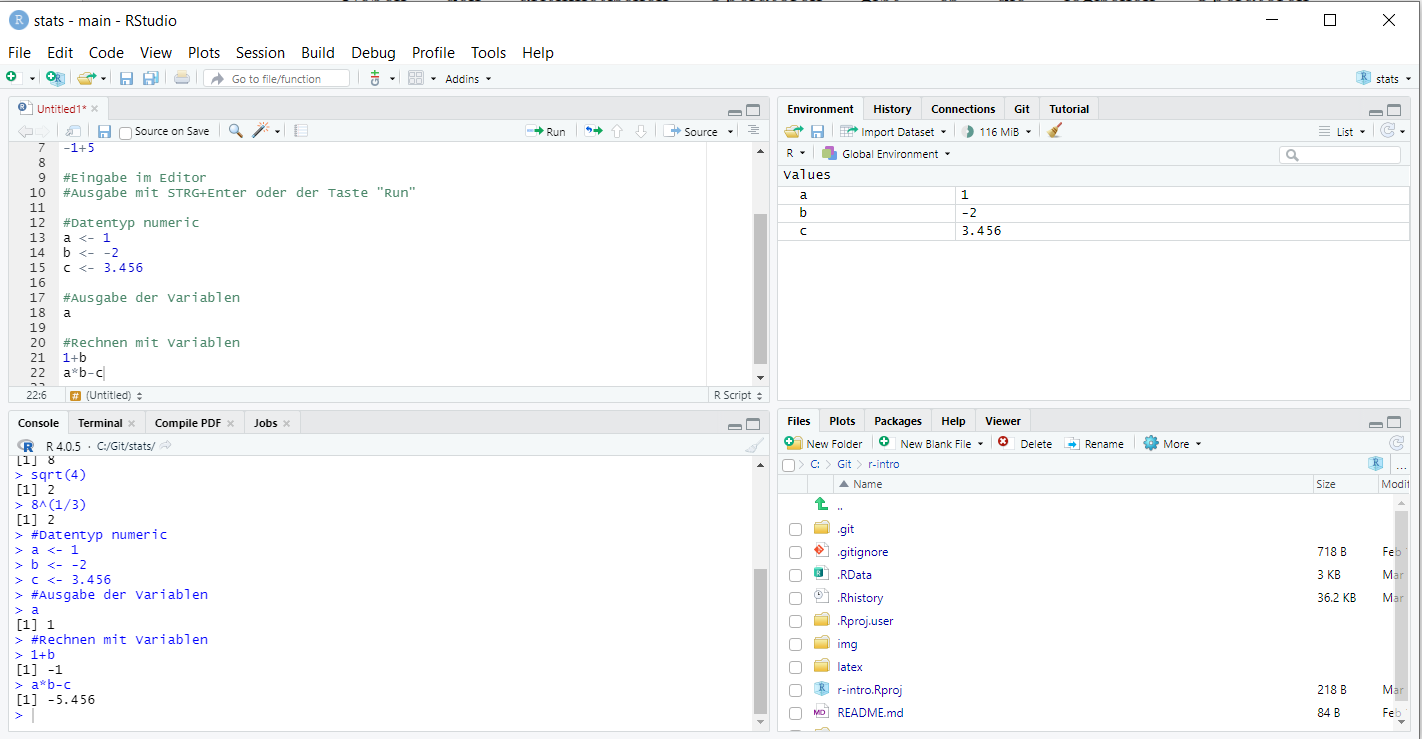
Zuweisungen können grundsätzlich auch mit einem = erfolgen, d.h. x = 5 würde ebenfalls der Variable x den Wert 5 zuweisen. Sie werden diese Schreibweise immer wieder in fremdem R-Code finden. Allerdings wird von dieser Schreibweise abgeraten, da das Gleichheitszeichen auch für die Definition von Parametern in Funktionen verwendet wird und damit zu Fehlern führen kann.
Möchte man ein Objekt wieder aus der Umgebung entfernen, geschieht dies über die Funktion rm, in unserem Fall also
rm(x)Möchte man mehrere Objekte in der Umgebung löschen, listet man diese in der Funktion rm einfach auf (z. B. rm(x,y)).
Möchte man sich alle Objekte in der aktuellen Environment anzeigen lassen, so geht dies mit der “List Objects” Funktion
ls()[1] "a" "umsatz" "y" "z" Alle verfügbaren Objekte werden mit Ihrem Namen (also in Anführungszeichen) aufgelistet. Zu diesem Zeitpunkt sind also nur noch a, y und z in der Umgebung verfügbar, da wir zuvor x entfernt haben. Möchten wir alle Objekte der Umgebung löschen, können wir dies mit dem Befehl
rm(list = ls())erledigen.
Einzelne oder mehrere Objekte aus einer Umgebung lassen sich in einer Datei abspeichern und später wieder laden. Hierfür gibt es die Befehle save und load. Für einzelne Objekte sind saveRDS und readRDS oft übersichtlicher.
save(y, z, file = "daten_yz.RData")Damit speichern Sie die Objekte y und z in der Datei daten_yz.RData im aktuellen Working Directory.
Wenn Sie stattdessen einen Unterordner nutzen möchten, muss dieser vorher existieren (oder angelegt werden):
dir.create("daten", showWarnings = FALSE)
save(y, z, file = "daten/daten_yz.RData")Mit dem Befehl
load(file = "daten_yz.RData")können wir zu einem späteren Zeitpunkt alle Objekte aus der Datei wieder in unsere Umgebung laden.
kundendaten <- data.frame(kunde = c("A", "B"), umsatz = c(1200, 980))
saveRDS(kundendaten, file = "kundendaten.rds")
# Später wieder laden:
kundendaten2 <- readRDS("kundendaten.rds")Mit dem load Befehl lassen sich nur R Objekte laden. Datensätze in Formaten wie Excel, als Textdatei oder gar in Datenbanken lassen sich hiermit nicht einlesen.
HinweisExkurs: Absolute und relative Pfade, Working Directory
- Working Directory: Der Ordner, von dem aus R gerade arbeitet (
getwd()). - Relativer Pfad: Bezieht sich auf das Working Directory, z.B.
kundendaten.rdsoderdaten/kundendaten.rds. - Absoluter Pfad: Vollständiger Pfad, z.B.
- Workbench/Linux:
/home/<kennung>/projekt/daten/kundendaten.rds - Windows lokal:
C:/Users/<name>/projekt/daten/kundendaten.rds
- Workbench/Linux:
Empfehlung: in Projekten möglichst relative Pfade verwenden.
VorsichtMini-Übung 4
- Prüfen Sie Ihr Working Directory mit
getwd(). - Speichern Sie ein Objekt mit
saveRDS(..., "test.rds"). - Laden Sie es mit
readRDS("test.rds"). - Löschen Sie es aus der Umgebung und laden Sie erneut.
5 Datentypen und Datenstrukturen
5.1 Atomische Datentypen
Wie in jeder Programmiersprache werden auch in R Daten in verschiedenen Typen abgespeichert. Ähnlich wie die Skalenniveaus aus der Statistik unterscheiden diese Typen die Daten nach Informationsgehalt (z. B. metrisch und nominal skalierte Daten). Außerdem wird über die Datentypen geregelt, wie R die Daten intern im Arbeitsspeicher ablegt.
Die von R verwendeten Datentypen sind
numeric: Dezimalzahleninteger: ganzzahlige Zahlencomplex: komplexe Zahlenlogical: logische Werte (d.h. wahr oder falsch, bzw. in RTRUEoderFALSE)character: Textzeichen
Um festzustellen, welcher Typ einem Objekt in R zugewiesen wurde, verwenden wir die Funktion mode
x <- 5
mode(x)[1] "numeric"y <- TRUE
mode(y)[1] "logical"Man kann auch die einzelnen Typen abfragen, indem man vor die Typenbezeichnung ein is.setzt:
is.numeric(x)[1] TRUEis.character(x)[1] FALSER gibt in diesem Fall ein TRUE oder FALSE zurück, je nachdem ob das Objekt den jeweiligen Datentyp besitzt. Mit einem as. gefolgt von der Typenbezeichnung lässt sich der Datentyp eines Objekts konvertieren:
x2 <- as.integer(x)
is.integer(x2)[1] TRUEx3 <- as.character(x)
mode(x3)[1] "character"x3[1] "5"Neben diesen Datentypen gibt es außerdem einige besondere Typen:
NaN: “Not a Number”, entsteht bei mathematisch unbestimmten Ausdrücken wie0/0oderInf - InfNA: “Not Available”, also fehlender WertNULL: leeres ObjektInf,-Inf: Unendlich (positiv und negativ), z.B. bei3/0bzw.-3/0
5.2 Datenstrukturen
Wenn wir mit Daten arbeiten, nutzen wir typischerweise Strukturen, um einzelne Zahlen zu größeren Objekten zusammenzufassen. Einfachste Beispiele hierfür sind Vektoren und Matrizen. Neben diesen gibt es weitere Datenstrukturen in R, mit denen man arbeiten kann. Sie unterscheiden sich im Wesentlich dadurch, wie viele Dimensionen sie umfassen
vector: Vektor – eindimensionale Kombination von atomischen Datenpunkten gleichen Typsmatrix: Matrix – zweidimensionale Kombination von atomischen Datenpunkten gleichen Typslist: Liste – eindimensionale Kombination von atomischen Datenpunkten unterschiedlichen Typsdata.frame: Data Frame – zweidimensionale Kombination von atomischen Datenpunkten unterschiedlichen Typs
Die Einordnung nach Dimensionen und Homogenität ist in Abbildung 7 zusammengefasst.

5.2.1 Vektoren
Einen Vektor können wir erstellen, indem wir mehrere atomare Objekte (oder andere Vektoren) mit Hilfe der “Combine”-Funktion verknüpfen:
x <- c(1200, 980, 1430) # z.B. Umsätze in EUR
x[1] 1200 980 1430Für ganzzahlige Zahlenfolgen können wir die Kurzschreibweise m:n verwenden:
x <- -5:5
x [1] -5 -4 -3 -2 -1 0 1 2 3 4 5Um auf einzelne Elemente aus einem Vektor zuzugreifen, geben wir in eckigen Klammern die Stellen im Vektor an, die zurückgegeben werden sollen. Diese Stellen nennt man auch Index.
x[1][1] -5x[4:5][1] -2 -1Ein vorangesetztes Minus-Zeichen ergibt, dass alle Elemente des Vektors ausgegeben werden außer diejenigen mit negativem Index
x[-1] [1] -4 -3 -2 -1 0 1 2 3 4 5x[-c(1,6)][1] -4 -3 -2 -1 1 2 3 4 5Über die Indizierung lassen sich auch einzelne Werte überschreiben
x[1] <- 10000
x [1] 10000 -4 -3 -2 -1 0 1 2 3 4 5Statt eines Index’ kann die Referenzierung auch mit Hilfe von logischen Werten erfolgen. Dazu ist ein logischer Vektor der gleichen Länge zu verwenden – die Rückgabe entspricht dann allen Einträgen, für die der logische Vektor gleich TRUE ist.
x <- 1:5
y <- c(TRUE, FALSE, TRUE, FALSE, TRUE)
x[y][1] 1 3 55.2.2 Matrizen
Matrizen sind Datenstrukturen mit zwei Dimensionen (Zeilen und Spalten).
Matrizen können direkt aus Vektoren erstellt werden:
x <- 1:12
m1 <- matrix(x, nrow = 3, byrow = TRUE)
m1 [,1] [,2] [,3] [,4]
[1,] 1 2 3 4
[2,] 5 6 7 8
[3,] 9 10 11 12m2 <- matrix(x, nrow = 4, byrow = FALSE)
m2 [,1] [,2] [,3]
[1,] 1 5 9
[2,] 2 6 10
[3,] 3 7 11
[4,] 4 8 12Auf die einzelnen Elemente aus einer Matrix kann man über die eckigen Klammern zugreifen, wobei die Dimensionen durch ein Komma getrennt werden. Bei einer Matrix entsprechen die Zeilen der ersten Dimension und die Spalten der zweiten Dimension. Das heißt, möchten wir von Matrix m1 das Element in der zweiten Zeile und dritten Spalte auswählen, erfolgt dies mit
m1[2,3][1] 7Auch hier könnte man wie bei Vektoren logische Werte für die Referenzierung verwenden.
Um ganze Zeilen oder Spalten auszuwählen, wird die jeweils andere Dimension leer gelassen. Es können auch mehrere Zeilen oder Spalten gleichzeitig gewählt werden. So ergibt sich zum Beispiel für m1 für die Auswahl der zweiten und vierten Spalte
m1[,c(2,4)] [,1] [,2]
[1,] 2 4
[2,] 6 8
[3,] 10 12Matrizen (und Vektoren) transponiert man mit der Funktion t
t(m1) [,1] [,2] [,3]
[1,] 1 5 9
[2,] 2 6 10
[3,] 3 7 11
[4,] 4 8 12Die gewöhnliche Addition oder Multiplikation (auch Potenzieren) von Skalaren mit Vektoren oder Matrizen erfolgt elementweise
3+x [1] 4 5 6 7 8 9 10 11 12 13 14 15x^2 [1] 1 4 9 16 25 36 49 64 81 100 121 1442*m1 [,1] [,2] [,3] [,4]
[1,] 2 4 6 8
[2,] 10 12 14 16
[3,] 18 20 22 24Das Skalarprodukt kann per %*% verwendet werden:
v1 <- 1:3
v2 <- 1:4
t(v1) %*% m1 %*% v2 [,1]
[1,] 500Vektoren und Matrizen enthalten immer nur einen Datentyp. Dieser wird immer gewählt als der Datentyp, in den sich alle einzelnen Elemente höchstens umwandeln lassen (je höher das Skalenniveau, umso besser). Eine Zahl kann beispielsweise leicht in einen Text bzw. Character umgewandelt werden, andersherum funktioniert das aber nicht.
x <- c(1,2,3,"R")
x[1] "1" "2" "3" "R"mode(x)[1] "character"as.numeric(x)Warning: NAs introduced by coercion[1] 1 2 3 NA5.2.3 Listen
Listen sind eindimensionale Datenstrukturen, welche jedoch in den einzelnen Elementen Daten unterschiedlichen Typs enthalten können. So kann eine Liste zum Beispiel im ersten Element eine Zahl enthalten und im zweiten einen Character. Das ist bei Vektoren wie oben gesehen nicht möglich.
x <- list(1,2,3,"R")
x[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3
[[4]]
[1] "R"Listen können auch als Elemente nicht-atomare (sogar beliebige) Datenstrukturen enthalten, zum Beispiel Vektoren, Matrizen oder andere Listen. Außerdem können einzelne Elemente mit einem Namen versehen werden.
l <- list(Vektor = 1:10,
Matrix = matrix(1:12, nrow = 3),
Character = c("a","b","c"))
l$Vektor
[1] 1 2 3 4 5 6 7 8 9 10
$Matrix
[,1] [,2] [,3] [,4]
[1,] 1 4 7 10
[2,] 2 5 8 11
[3,] 3 6 9 12
$Character
[1] "a" "b" "c"RStudio hilft dabei, durch sinnvolle Einrückungen den Code lesbarer zu machen. Im obigen Beispiel hilft der Zeilenumbruch nach jedem definierten Listenelement dabei, dass der Code nicht in einer sehr langen Zeile resultiert. Die Einrückungen nach dem Zeilenumbruch macht RStudio automatisch, und zwar so, dass der Code logisch strukturiert und gut lesbar ist.
Auf einzelne Listenelemente kann man auf verschiedene Arten zugreifen – entweder über einen Index in doppelten eckigen Klammern, über die Referenzierung mit logischen Werten oder über den Namen des Listenelements nach einem Dollarzeichen:
l[[1]] [1] 1 2 3 4 5 6 7 8 9 10l$Vektor [1] 1 2 3 4 5 6 7 8 9 105.2.4 Data Frames
Der Data Frame ist die Datenstruktur, die in R wahrscheinlich am häufigsten zur Anwendung kommt. Ein Data Frame entspricht dem, wie wir uns eine typische Datentabelle vorstellen. Ähnlich wie eine Matrix hat ein Data Frame zwei Dimensionen (Zeilen und Spalten). Die Spalten entsprechen dabei den Variablen, die Zeilen den Beobachtungen des Datensatzes. Entsprechend kann im Unterschied zu einer Matrix jede Spalte eines Data Frames einen unterschiedlichen Datentyp haben (z. B. numerisch als numeric, kategoriell als factor), was uns wiederum an Listen erinnert. Spalten und Zeilen von Data Frames bekommen Namen.
Im Grunde sind Data Frames nichts anderes als Listen, die etwas anders dargestellt werden und einige Einschränkungen haben (z. B. jedes Listenelement = Spalte ist ein Vektor und gleich lang). Mehr dazu: Advanced R: Data frames.
Data Frames lassen sich neu definieren, aus Matrizen erstellen, oder auch aus externen Datenquellen einlesen.
as.data.frame(m1) V1 V2 V3 V4
1 1 2 3 4
2 5 6 7 8
3 9 10 11 12Wenn nicht anders angegeben, lauten die Namen der Zeilen 1,2,3,… und die Namen der Spalten V1, V2, V3, … – es können aber auch Namen bei der Definition angegeben werden
df <- data.frame(
Kunde = c("K001", "K002", "K003", "K004", "K005"),
Umsatz = c(1200, 950, 1430, 870, 1110),
Premiumkunde = c(TRUE, FALSE, FALSE, TRUE, TRUE)
)
df Kunde Umsatz Premiumkunde
1 K001 1200 TRUE
2 K002 950 FALSE
3 K003 1430 FALSE
4 K004 870 TRUE
5 K005 1110 TRUEÄhnlich wie bei Listen, kann auch bei Data Frames der Zugriff auf einzelne Elemente über die Namen oder Indizes erfolgen:
df$Umsatz[1] 1200 950 1430 870 1110df[3,] Kunde Umsatz Premiumkunde
3 K003 1430 FALSEdf[1,2][1] 1200
VorsichtMini-Übung 5
Legen Sie einen kleinen Kunden-Data-Frame an und berechnen Sie den Durchschnittsumsatz:
kunden <- data.frame(
kunde = c("K001", "K002", "K003", "K004"),
umsatz = c(1200, 950, 1430, 870),
premium = c(TRUE, FALSE, TRUE, FALSE)
)
mean(kunden$umsatz)R enthält viele Datensätze (als Data Frames), mit denen man üben und Algorithmen testen kann. Es gibt dafür ein spezielles Paket, welches in der Basis-Installation von R bereits enthalten ist: datasets (für eine Übersicht: help(package = "datasets")). Diese Datensätze lassen sich ganz einfach mit ihrem Namen aufrufen, z. B. der Datensatz iris ist bereits in der Umgebung verfügbar und kann direkt verwendet werden.3
5.2.5 Kategorielle Variablen
In der Statistik arbeitet man häufig mit ordinal oder nominal skalierten Daten. Hierfür bietet R einen speziellen Datentyp: factor.
Ein factor wird in R intern als Merkmal mit ganzzahligen Ausprägungen gespeichert. Jeder dieser Ausprägungen kann ein “Label” vergeben werden. Faktoren lassen sich zum Beispiel aus character-Vektoren erstellen:
automarke_chr <- c("Opel", "BMW", "Mercedes", "Mercedes", "Opel", "BMW")
automarke_factor <- factor(automarke_chr)
automarke_chr[1] "Opel" "BMW" "Mercedes" "Mercedes" "Opel" "BMW" automarke_factor[1] Opel BMW Mercedes Mercedes Opel BMW
Levels: BMW Mercedes OpelBei der Ausgabe eines Faktors werden die Beobachtungen angezeigt und auch eine Übersicht über die enthaltenen Faktorlevels (Kategorien) gegeben. Auf diese kann man auch über die Funktion levels zugreifen und die Bezeichnungen gegebenenfalls überschreiben:
levels(automarke_factor)[1] "BMW" "Mercedes" "Opel" levels(automarke_factor)[2] <- "Mercedes Benz"
automarke_factor[1] Opel BMW Mercedes Benz Mercedes Benz Opel
[6] BMW
Levels: BMW Mercedes Benz OpelFür einen Faktor mit definierten Faktorlevels können keine Beobachtungen mit anderen Faktorlevels eingetragen werden
automarke_factor[1] <- "BMW"
automarke_factor[1] BMW BMW Mercedes Benz Mercedes Benz Opel
[6] BMW
Levels: BMW Mercedes Benz Opelautomarke_factor[1] <- "Audi"Warning in `[<-.factor`(`*tmp*`, 1, value = "Audi"): invalid factor level, NA
generatedautomarke_factor[1] <NA> BMW Mercedes Benz Mercedes Benz Opel
[6] BMW
Levels: BMW Mercedes Benz OpelDazu muss zunächst ein zusätzliches Faktorlevel definiert werden
levels(automarke_factor) <- c(levels(automarke_factor), "Audi")
automarke_factor[1] <NA> BMW Mercedes Benz Mercedes Benz Opel
[6] BMW
Levels: BMW Mercedes Benz Opel Audiautomarke_factor[1] <- "Audi"
automarke_factor[1] Audi BMW Mercedes Benz Mercedes Benz Opel
[6] BMW
Levels: BMW Mercedes Benz Opel AudiIntern werden die Faktorstufen als Integer abgespeichert (in der Reihenfolge der Faktorlevels beginnend mit 1, also hier: BMW = 1, Mercedes Benz = 2, Opel = 3 und Audi = 4). Wenn man einen Faktor in einen numeric umwandelt, entsprechen die Elemente diesen Werten.
as.numeric(automarke_factor)[1] 4 1 2 2 3 1
VorsichtMini-Übung 6
Erstellen Sie einen Faktor für Produktkategorien und prüfen Sie die Levels:
kategorie <- factor(c("A", "B", "A", "C", "B"))
levels(kategorie)
table(kategorie)Neben den hier vorgestellten Datentypen gibt es noch viele weitere, die jeweils für spezielle Aufgaben gedacht sind. So gibt es beispielsweise Datentypen für Datum, Zeitreihen, Geokoordinaten etc., welche an dieser Stelle nicht im Detail vorgestellt werden.
5.2.6 Ermitteln der Struktur eines Objektes
Strukturen von Objekten können sehr komplex und verschachtelt sein (z. B. Listen mit vielen verschiedenen Datentypen). Die Funktion str fasst die Struktur zusammen und macht sie so transparent. Sie gibt die interne Struktur eines R Objekts zurück. Für jedes grundlegende Strukturelement gibt sie eine Zeile mit den wesentlichen Informationen zurück. Für die Liste l ist dies der Typ, die Größe und einige Werte der Listenelemente.
str(l)List of 3
$ Vektor : int [1:10] 1 2 3 4 5 6 7 8 9 10
$ Matrix : int [1:3, 1:4] 1 2 3 4 5 6 7 8 9 10 ...
$ Character: chr [1:3] "a" "b" "c"Für den Data Frame df wird die Anzahl Beobachtungen und Variablen angegeben, sowie eine kurze Übersicht über jede einzelne Variable.
str(df)'data.frame': 5 obs. of 3 variables:
$ Kunde : chr "K001" "K002" "K003" "K004" ...
$ Umsatz : num 1200 950 1430 870 1110
$ Premiumkunde: logi TRUE FALSE FALSE TRUE TRUE
TippNächster Schritt
Die deskriptive Statistik wird in dieser Veranstaltung in eigenen Unterlagen behandelt. Dieser Abschnitt fokussiert daher auf den sicheren Umgang mit R, RStudio und grundlegenden Datenstrukturen.
6 Weiterführende Ressourcen
- Posit Cheatsheets (Übersicht): https://posit.co/resources/cheatsheets/
- RStudio IDE Cheat Sheet (direkt): https://posit.co/wp-content/uploads/2022/10/rstudio-ide.pdf
- Base R Reference Card: https://cran.r-project.org/doc/contrib/Short-refcard.pdf
- R for Data Science: https://r4ds.hadley.nz/
- R Dokumentation (Suche): https://search.r-project.org/
Fußnoten
Informationen, wie Sie sich per VPN mit den Netzen der Fachhochschule verbinden, finden Sie unter https://confluence.fh-muenster.de/display/howto/VPN↩︎
Informationen zur Einrichtung der Zweifaktorauthentifizierung erhalten Sie unter https://confluence.fh-muenster.de/display/howto/Multi-Faktor-Authentifizierung↩︎
Der Datensatz liegt streng genommen in der Environment des Pakets
datasets. Da dieses Paket beim Start von R automatisch geladen wird, ist der Datensatz immer verfügbar.↩︎